Kruskal's algorithm is a greedy algorithm that finds a minimum spanning tree(MST) of an undirected, connected weighted graph.
In this post, we will generate mazes from a randomized version of Kruskal's algorithm.
I used D3 for the animation, and the code can be found on my Observable.
Minimum spanning trees
A minimum spanning tree contains:
every node of the graph
a subset of the edges
The sum of the edge weights is minimized, and there are no cycles.
If the graph is not connected, Kruskal finds a minimum spanning tree for each connected component, resulting in a minimum spanning forest.
Other uses of minimum spanning trees
Just a couple of real world examples...
Network Design
Minimum spanning trees are often used in network design, for example to plan out laying an electrical grid that connects all the houses in a neighborhood.
You might want to lay out the grid in such a way that minimizes cost. The houses are nodes in the graph, with edges connecting them. In this case the edge weight would be the cost of connecting two houses.
An MST would give you a design that connects all of the houses in the cheapest way.
Image Segmentation
An image is usually represented as a grid of pixels, which can be thought of as a graph. A pixel or group of pixels represents each node in the graph, and the edges between them have weights based on some similarity metric such as difference in their pixel intensities. Read more about that here.
Generating random mazes
We start with a grid of nodes, with edges between each pair of neighbors in the four cardinal directions.
Points along the border have fewer neighbors.
I'm using this rainbow gradient of colors for the nodes for a reason!
The colors will help illustrate a key concept in this algorithm that I will get to in a bit.
Since the graph is undirected we only need to store each edge once.
So if there is an edge from node (0,0) to (0,1), we do not also need to store the edge (0,1) to (0,0).
Random weights
We will assign random weights to the edges in this graph.
Kruskal's algorithm
We have the nodes and edges of the graph. Now, what to do with them?
Ultimately we want to end up with a single MST.
Union-find
We are going to use a union-find algorithm, also known as a disjoint set, to determine which edges will be part of our solution MST.
It's hard to come up with 400 different colors for each node in this 20x20 grid, but each node color in the grid above is slightly different!
I'm not going to get into the rest of the D3 code for the animation in this post.
To start off, each node points to itself as the root of its own tree, but after we are done finding the MST, the nodes should all be part of the same tree.
So at the end of the animation, notice that the nodes are all the same color, because they are all part of the same tree.
Sort the edges
First we are going to sort of the edges by weight, which are the random weights we assigned earlier.
By sorting them, we will be looking at the smallest edges first to add to the minimum spanning tree.
Side note: for the animation, I shuffled the edges before sorting them by weight, to make for a more interesting visualization.
We iterate through the edges, and first check to see which tree each node is in.
If the two nodes are not in the same tree, then we can join them together and add the edge to the solution.
If they are part of the same tree, then we just discard that edge.
The main thing to worry about is whether or not we will create a cycle, which we would do if we added an edge where the nodes were already in the same tree.
Kruskal's algorithm is a greedy algorithm because for each step, it takes the optimal choice at the time by adding the smallest edge that won't create an invalid solution.
Find
From earlier, each tree u is represented by its root node, clusters[u], so if the two points have the same root node, they are in the same tree.
The find function returns the root of a node's tree and updates clusters so that the nodes along the path from u to the root are all pointing to the root.
Path compression
Updating clusters like this is called path compression and works to flatten the tree.
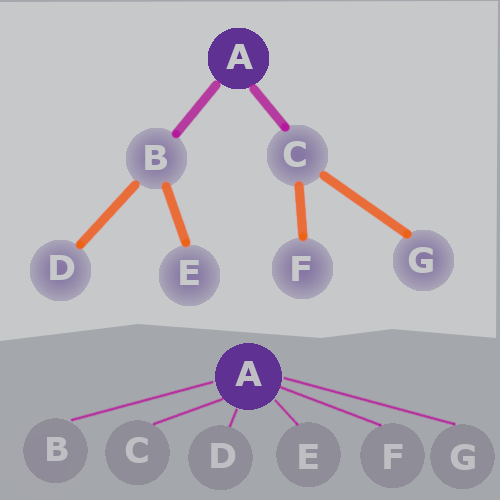
If we have this tree with root A.
there are children nodes, B and C
and grandchildren nodes, D, E, F, G
The grandchildren nodes are still part of A's tree, so if we call find on them, it will update the whole path to point to A.
For example, find(D) would update all nodes in the path from D to A to point to A. In this case, that would only mean updating D, because B already points to A.
If we called find of all of the grandchildren, we would end up with a tree like the one in the bottom of the graphic.
This speeds up the algorithm because subsequent calls to find for a node u will immediately return the root node, rather than having to traverse the same path again.
Union
If the two nodes are not in the same tree, then the edge can be added to the solution, which joins the two trees together.
In the animation, notice how two trees, or clusters of edges, have different colors, and then a new edge is added to the solution that connects them and they all become the same color.
When adding a new edge to the solution, you have to decide how to join the two trees together.
Should the first tree be joined to the second tree, or vice versa?
This is where the ranks from earlier come in.
const union = (x,y) => {
x = find(x,x);
y = find(y,y);
if(ranks[x] > ranks[y]){
clusters[y] = x;
}else{
clusters[x] = y;
}
if(ranks[x] == ranks[y]){
ranks[y]++;
}
}
If x's rank is higher, then we add y to x's tree.
If y's rank is higher, or equal, then we add x to y's tree.
If the ranks are equal, then we will increment y's rank by one to break the tie.
Putting it all together
So the whole thing can be summed up like this:
Generate nodes and edges from the grid, and assign random weights to each edge.
Sort the edges by weight.
Iterate through the edges.
For each edge, check if the two nodes are part of the same tree.
If they are not, add the edge to the solution. Otherwise, discard the edge.
solution = new Set();
//add random weight to each edge
let weightedEdges = graph.edges.map((e) => {
e.weight = getRandomInt(1,5);
return e;
});
//sort the edges by weight
weightedEdges = weightedEdges.sort((a, b) => (a.weight > b.weight) ? 1 : -1);
//iterate through the edges and add to solution or discard
for(let edge of weightedEdges){
let x = edge.source.id,
y = edge.target.id;
if(x != y){
if(find(x) != find(y)){
union(x,y);
solution.add(edge.id);
}
}
Now the solution set of edges will make up the minimum spanning tree, and also indicates the legal paths you can traverse to solve the maze.
Thanks for reading!
I hope this was helpful to you. Feel free to reach out with any questions or comments!
Starting out with general purpose computing on the GPU, we are going to write a WebGPU compute shader to compute Morton Codes from an array of 3-D coordinates. This is the first step to detecting collisions between pairs of points.
In this post, I am dipping my toes into the world of compute shaders in WebGPU. This is the first of a series on building a particle simulation with collision detection using the GPU.
Finding the Lowest Common Ancestor of a pair of nodes in a tree can be helpful in a variety of problems in areas such as information retrieval, where it is used with suffix trees for string matching. Read on for the basics of this in Python.