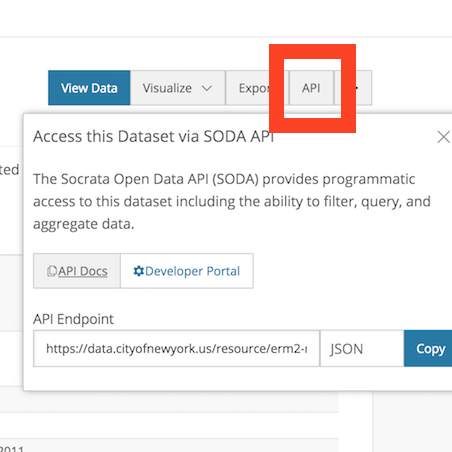
You can view the API docs for this dataset, and also get the API endpoint link - note the endpoint link because we will need it next.
In a new file, go ahead and import the requests library, as well as your app token and the endpoint link.
import requests
NYC_OPEN_DATA_API_KEY = 'xxxxxxxxxxx'
endpoint = 'https://data.cityofnewyork.us/resource/erm2-nwe9.json'
As always, I would caution everyone to keep their App tokens(or any api keys) in some kind of configuration file or as an environment variable outside of your program. I like Python-decouple for this.
Now we can make a basic GET request for the data, adding the App token to the request as a header.
headers={'X-App-Token': NYC_OPEN_DATA_API_KEY}
result = requests.get(endpoint, headers=headers)
Notice at the end of the API endpoint, I've used the .json extension, so the returned results will be in JSON format.
The requests library has a built-in JSON decoder, so you can simply call result.json() to access the data.
Let's look at the first row.
result.json()[0]
{'unique_key': '45451683',
'created_date': '2020-01-23T01:59:26.000',
'agency': 'NYPD',
'agency_name': 'New York City Police Department',
'complaint_type': 'Noise - Residential',
'descriptor': 'Banging/Pounding',
'location_type': 'Residential Building/House',
'incident_zip': '10470',
'incident_address': 'XXX EAST XXX STREET',
'street_name': 'EAST XXX STREET',
'cross_street_1': 'XXX AVENUE',
'cross_street_2': 'XXX AVENUE',
'intersection_street_1': 'XXX AVENUE',
'intersection_street_2': 'XXX AVENUE',
'city': 'BRONX',
'landmark': 'EAST XXX STREET',
'status': 'In Progress',
'community_board': '12 BRONX',
'bbl': '2033820050',
'borough': 'BRONX',
'x_coordinate_state_plane': '1021274',
'y_coordinate_state_plane': '266111',
'open_data_channel_type': 'MOBILE',
'park_facility_name': 'Unspecified',
'park_borough': 'BRONX',
'latitude': '40.89700924172494',
'longitude': '-73.86607891380385',
'location': {'latitude': '40.89700924172494',
'longitude': '-73.86607891380385',
'human_address': '{"address": "", "city": "", "state": "", "zip": ""}'},
':@computed_region_efsh_h5xi': '11608',
':@computed_region_f5dn_yrer': '29',
':@computed_region_yeji_bk3q': '5',
':@computed_region_92fq_4b7q': '40',
':@computed_region_sbqj_enih': '30'}
Note: I've edited this data a bit - specifically street addresses and cross streets - just to make it a bit less easily identifiable.
In the docs you can find information about each of these fields and which data type each field is.
For example, the created_date field is a floating timestamp, and the agency_name field is a text field.
If you wanted to get this data in another format, such as XML, you could change the ending of the endpoint to '.xml'.
endpoint = 'https://data.cityofnewyork.us/resource/erm2-nwe9.xml'
And then parse the response in your preferred way.
Filtering data
You can filter data either by using Simple Filters or SoQL Queries.
Simple equality filters
To perform a simple equality filter, you just use the field name and value you want to filter by.
endpoint = 'https://data.cityofnewyork.us/resource/erm2-nwe9.json?complaint_type={}'.format("HEAT/HOT WATER")
The part after the '?' is the filter:
complaint_type=HEAT/HOT WATER
Here I am querying for complaint_type and am looking for complaints about heat and hot water.
Look at the data to see what the value looks like for whatever you're trying to filter by, so that you can match it correctly.
SoQL Queries
Socrata Query Language, or SoQL, is similar to SQL and allows you to create a query using parameters such as $select, $where, $order, $group, $having and others that you might be familiar with if you have used SQL.
The $q parameter can be used to perform a full text search for a value.
Check out the docs for more.
A couple of other parameters available are $limit and $offset which we will use in the next section on pagination.
Heat and hot water complaints in the last five days
If I wanted to filter for heat and hot water complaints that were created within the past five days, I would use a SoQL query.
from datetime import datetime,timedelta
five_days_ago = datetime.date(datetime.now()) - timedelta(5)
endpoint = "https://data.cityofnewyork.us/resource/erm2-nwe9.json?$select=created_date,complaint_type,city,status&$where=created_date>='{}'&complaint_type={}".format(str(five_days_ago),"HEAT/HOT WATER")
The SoQL query is the part after the '?' in the URL.
$select=created_date,complaint_type,city,status&$where=created_date>='2020-01-20'&complaint_type=HEAT/HOT WATER
I used the timedelta function in Python's datetime module to find the date for 5 days earlier than datetime.now().
The $select clause tells it to return only the columns for created_date,complaint_type,city and status.
If you leave out the $select clause, it will just return all of the columns.
This $where clause tells it to return rows if the date is greater than or equal to January 20, 2020. I'm writing this on January 25th, so that is five days prior, as well as the complaint_type of heat and hot water.
Here is part of the result:
[...
{'created_date': '2020-01-20T17:23:19.000',
'complaint_type': 'HEAT/HOT WATER',
'city': 'BROOKLYN',
'status': 'Closed'},
{'created_date': '2020-01-20T17:23:56.000',
'complaint_type': 'HEAT/HOT WATER',
'city': 'BRONX',
'status': 'Closed'},
{'created_date': '2020-01-20T17:23:58.000',
'complaint_type': 'HEAT/HOT WATER',
'city': 'BROOKLYN',
'status': 'Open'}]
Notice that I have the single quotes around the date in the URL. I used string formatting, but I need the actual quote marks in there as well.
If you try the request without the quotes around the date, you will get a 400 error for 'Invalid SoQL query'.
Pagination
I mentioned the $limit and $offset parameters previously, and we will use them here for pagination.
The $limit defaults to 1000 results.
For the query that we just did, we got back 1000 results, but that's not all of the results.
There used to be a limit of 50,000 records for the $limit clause, but as of version 2.1 of the API there is no limit and they advise you to pick a limit that is appropriate for your internet connection so that the request will not time out.
From the docs, when paging through data, you want to use the $order clause, which guarantees that the order of your results will remain stable as you page through. Otherwise the order of query results are not ordered in a particular way.
If you don't care about the order otherwise, you could just use $order=:id.
To get the next 1000 results, you will use an $offset of 1000, and as you page through, increase the offset by 1000 with each page you request.
$select=created_date,complaint_type,city,status&$where=created_date>='2020-01-20'&complaint_type=HEAT/HOT WATER&$order=:id&$offset=1000
The offset clause just lets the API know that you've already seen that number of results, and to return the next results starting after that.
You can read more about paging through data here.
GIS data
Lastly, I just wanted to mention that GeoJSON is another one of the formats that you can get back from the API.
I won't go into that here, but you can read the docs for more.
Thanks for reading
Let me know if you've used open data(NYC or otherwise) in any of your projects so I can check them out!
And of course, if you have any questions or comments, write them below or reach out to me on Twitter @LVNGD.