First I've supplied a list of input ingredients to the algorithm.
input_ingredients = ['rum', 'cola', 'lemon juice', 'ginger beer', 'vodka']
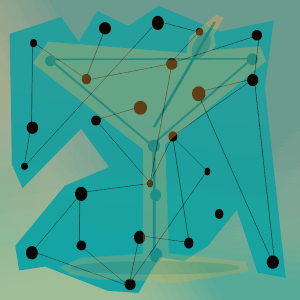
In general the algorithm will conduct a search for all cocktail possibilities from a list of input ingredients.
- A green node means it is part of a match for a cocktail recipe.
- A yellow node means that the path was explored but ended that that node because a cocktail could not be created from the combination of ingredients.
- Orange means the node is currently being considered.
The cocktail matches here were rum & coke(self explanatory) and dark & stormy, which at its most basic has ginger beer and rum.
The graph was created with D3.js and the code is in the Github repo for this project.
Input ingredients
The program takes a list of ingredients as input, so the idea is you could input whatever ingredients you have on hand to get cocktail suggestions to make with them.
Dealing with inputs could get pretty complicated - if you were going to make this into an app, users might enter all kinds of things for their input ingredients, and you want to be able to match up their ingredient list with ingredients in the graph.
In different recipes, there seem to be many different ways of listing an ingredient.
Coffee liqueur is sometimes listed as Kahlua, for example.
I've seen other ingredients listed as their brand name as well, so there are a lot of things to consider.
I'm not going to focus too much on standardizing the ingredients in this post because I mainly wanted to demonstrate using a graph for this problem.
Creating the graph and lookup tables
First we have to worry about creating the graph.
In this case I'm reading in the recipes from a text file and creating a graph from them.
A graph can be represented in a lot of ways, and in this case it's going to be a dictionary where the keys are ingredient names, with values being a set of compatible ingredients.
I'm using sets because I will be doing a lot of checking to see if the set contains an item, and with sets that can be done in constant time.
If I used a list, it would take up to linear time to check if the list contains an item because it would loop through the items in the list to find it. In order to find out an item does not exist in the list, it would have to loop through all of the items.
Read about time complexity of Python data structures here.
{
...
'pineapple juice': {'lime juice', 'cream of coconut', 'rum', 'campari', 'egg white', 'simple syrup'}
}
It's an undirected graph, so pineapple juice will also be found in the compatible ingredients set for lime juice, cream of coconut, etc.
Lookup tables
I've also created two lookup tables.
One is cocktails_to_ingredients, which is a dictionary with the cocktail name as the key and a set of ingredients as the value.
{
...
'screwdriver': {'vodka', 'orange juice'}
}
Pretty self-explanatory - a screwdriver contains vodka and orange juice.
The other lookup table is ingredients_to_cocktails, and is another dictionary with an ingredient as the key, and the value is a set of cocktail names that the ingredient can be found in.
{
...
{'orange juice': {'hurricane', 'easter egg hunt martini', 'tequila sunrise', 'mimosa', 'screwdriver'}
}
Orange juice is found in several drink recipes: hurricane, easter egg hunt martini, tequila sunrise, mimosa, and, of course, in a screwdriver.
Generating cocktail recommendations from the graph
Now the graph is ready and it's time to figure out what cocktails we can make with the ingredients we have.
How to do that?
By traversing the graph, starting from each input ingredient, and walking along a path of other compatible cocktail ingredients that are also found in the input ingredients.
As we traverse the path, the ingredients in the path so far will be checked to see if they make a valid cocktail(more on that later) or if they are a match to a cocktail recipe in cocktails_to_ingredients.
Depth-first search
Reminder the code is here.
In the function make_cocktail we will be iterating through each input ingredient and performing a depth-first search from that ingredient in the graph.
There are five input ingredients, so we will perform the depth-first search five times.
If an input ingredient is not found in the graph, it just skips that ingredient and goes to the next one in the list.
In this case, we want to only find cocktail matches that can be made from ingredients in the input list, so for each step in the search path, the algorithm gets the neighbors of that ingredient's node, which are the compatible ingredients, and checks to see which ones are in the input ingredient list.
Then it tentatively adds the new ingredient to a cocktail recipe list and checks to see if the ingredients in the list are a valid cocktail.
Valid cocktail ingredient combinations
A valid combination means that the ingredients can be found together in at least one cocktail recipe, so the path is potentially on the way to a full cocktail recipe match, if not a match already.
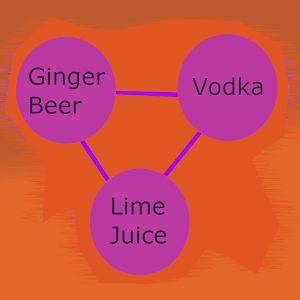
For example, if we were traversing the graph and started with ginger beer, one of its neighbors is the lime juice node.
These two ingredients can be found together in the Moscow Mule recipe, so it is a valid cocktail even if it's not a complete recipe match.
So these two ingredients would make a valid cocktail, and we will want to explore lime juice further, so it gets added to the stack to explore next.
On the other hand, if we were traversing from ginger beer to some other node, like triple sec, and those two ingredients cannot be found together in any cocktail recipe in this graph, then it would not be considered valid, so that search path would be abandoned.
Set intersection to find common cocktails that can be made with ingredients
The valid_cocktail function takes the current ingredients being considered and determines whether or not they are found in any cocktails together.
I did this with set intersection, which finds the common elements of sets.
Here I used the ingredients_to_cocktails lookup table that I mentioned earlier, and for each ingredient I lookup the cocktails it can be found in and in a loop get the intersection of the sets of cocktails that can be made with each ingredient.
The resulting set would contain any cocktails that contain all of the ingredients we are considering.
If the resulting set is ever empty, then it's not a valid ingredient combination and returns False.
Cocktail matches and partial matches
After checking to see if a set of ingredients is valid, we also want to see if there are any exact matches, as well as we might want to see if there are any partial matches.
The function matching_cocktails just loops through the lookup table dictionary cocktails_to_ingredients and checks to see if the ingredients under consideration match with any recipes exactly.
A ratio can also be set, and it will check to see if there are any recipes where the ingredients list makes up at least that much of the recipe.
So if we set the ratio at 0.5, we get partial matches if the input ingredients make up at least 50% of a recipe.
missing_ingredients = recipe_ingredients - ingredients
ratio = len(missing_ingredients) / len(recipe_ingredients)
if ratio > 0 and ratio < self.ratio:
#missing ingredients make up less than the ratio
Here recipe_ingredients and ingredients are both sets, so missing ingredients is the difference between them.
Maybe you want to see partial match cocktail ideas that mostly contain the input ingredients list, and if you only need an ingredient or two you could pick it up at the store, or even decide it's not necessary and omit it.
Let's try it out
We saw the visualization earlier that showed the graph of ingredients and then some of the path-finding that takes place, but the program itself will output the cocktails that can be made from a list of ingredients.
I'll use the same input list that I used for the simulation graph earlier.
input_ingredients = ['rum', 'cola', 'lemon juice', 'ginger beer', 'vodka']
Initialize the CocktailSuggester class, and I'm going to give it a ratio of 0.5 to get some partial match recommendations as well.
cocktails = CocktailSuggester(input_ingredients, ratio=0.5)
And print out the matching cocktails, along with their full recipes, which I'm getting from the cocktails_to_ingredients lookup table we talked about earlier.
for option in cocktails.cocktail_matches:
print(option, cocktails.cocktails_to_ingredients[option])
dark and stormy {'rum', 'ginger beer'}
rum and coke {'rum', 'cola'}
Then we can also print out the partial matches.
Partial matches are a dictionary of the cocktail name, along with the ingredients you're missing that you would need to make it.
for partial_cocktail,missing_ingredients in cocktails.partial_cocktails.items():
print("if you had {} you could make {} - {}".format(missing_ingredients,partial_cocktail, cocktails.cocktails_to_ingredients[partial_cocktail]))
if you had {'lime juice'} you could make cuba libre - {'rum', 'cola', 'lime juice'}
if you had {'lime juice'} you could make moscow mule - {'vodka', 'ginger beer', 'lime juice'}
Cheers!
And that's it, thanks for reading.
So obviously this cocktail suggester depends on recipes it already knows to make the suggestions, and is not going to come up with some crazy new drink on the fly.
If you were designing something like this, how would you extend it to suggest new drinks it doesn't already know?
There are also probably a million ways to improve this algorithm and make it faster or cleaner - how would you do that?
Let me know in the comments, or in Twitter @LVNGD.